Understanding Manipulation Contexts by Vision and Language for Robotic Vision
In Activities of Daily Living (ADLs), humans perform thousands of arm and hand object manipulation tasks, such as picking, pouring and drinking a drink. In a pouring manipulation task, its manipulation context involves a sequence of actions executed over time over some specific objects. Those actions, performed by a human actor, can include:
- Grasp an object that contains the liquid.
- Move the object over an empty containe.
- Pour the liquid into the empty container.
- Put the object back after finishing the pouring.
The human process of interpreting manipulation knowledge can be decomposed into three steps, see the figure below:
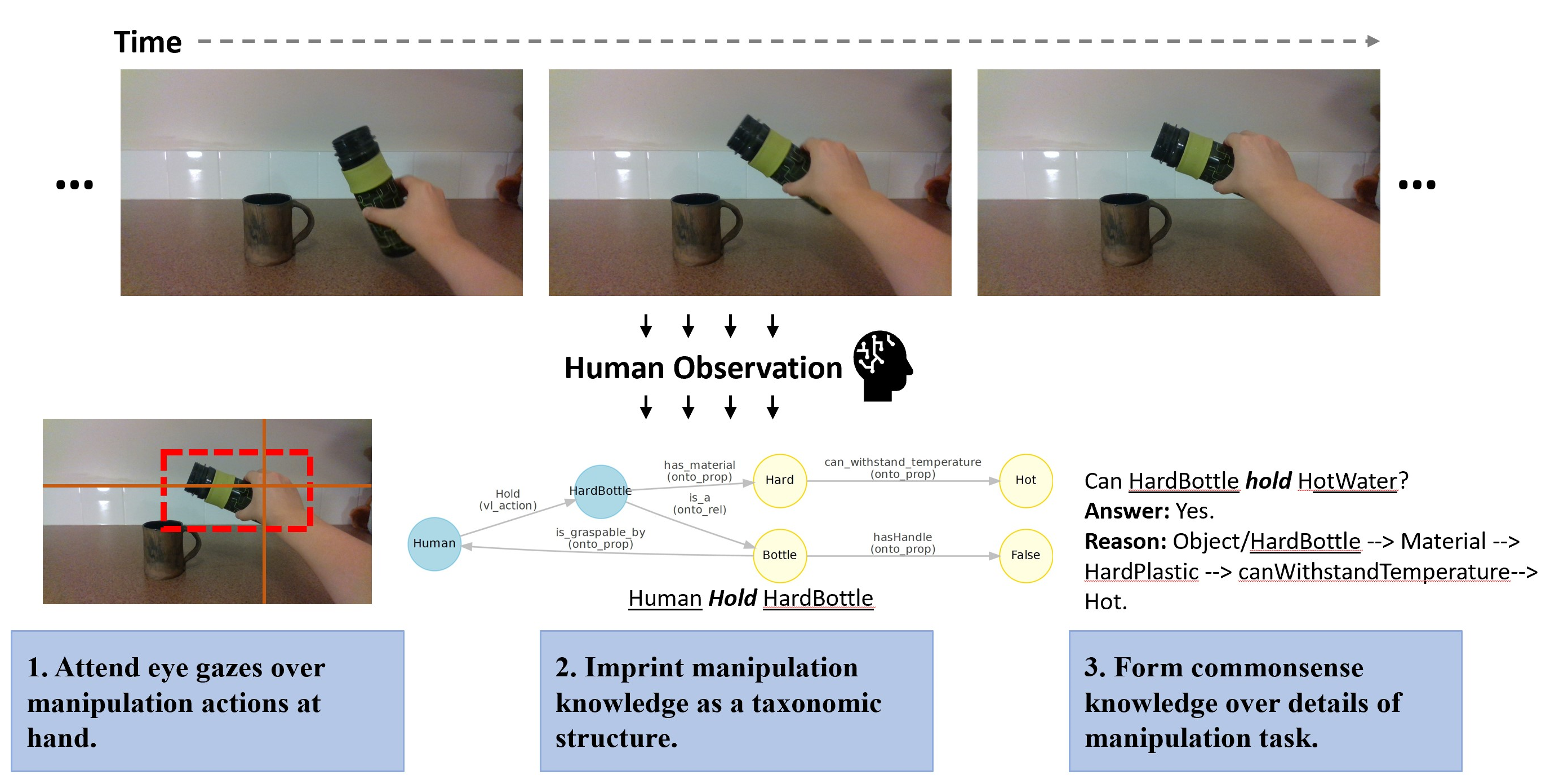
First, from hand-eye coordination, eye gaze will provide visual attention over the manipulation scene. Second, describing relationship between manipulation actor, action and objects such that a taxonomic structure will be able to represent the current manipulation context. Third, commonsense knowledge will allow humans to reason with manipulation concepts and deduct facts for current scenario, based on past experience. Eventually, for an intelligent robot to assist or to mimic humans in Activities of Daily Living (ADLs), a similar procedure of decomposing and analyzing manipulation contexts needs to be carried out first by the robot before enacting smart behaviors.
Recent advances in fusing computer vision with domain knowledge have enabled research in the area of intelligent robots. Studies both in robotic vision [1][2][3] and NLP - Natural Language Processing [4][5] provide promising tools for robots to better understand human tasks and assist humans in their daily life environment. Still, intelligent robots are far from perfect. The challenges for intelligent robots lie in their abilities to: (1) interpret sensor inputs of vision and contact interactions through modeling over daily life knowledge and commonsense reasoning, and (2) perform smart actions given factors including physical environment and human intentions. Various published works analyze human behaviors for robots to mimic, from attending to human eye gazes [6][7], to structuring ways of manipulations [8][9][10][11]. Still, none of the studies have offered a general solution to construct cognition for daily life robotics.
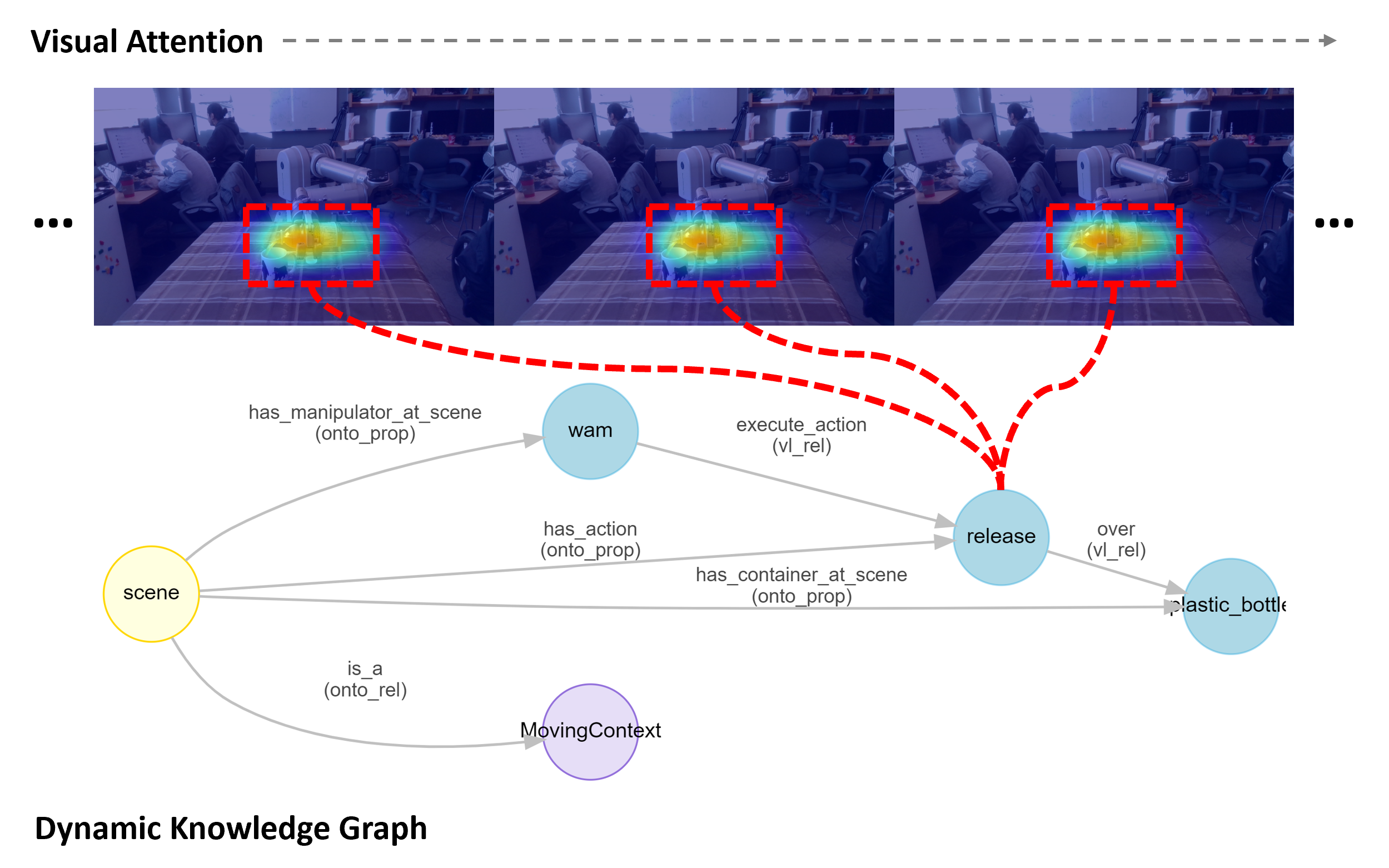
Given the visual observations of the manipulation scene over time, we aim to estimate their visual attentions and describe the internal relational structures of all presenting manipulation concepts into a dynamic knowledge graph. In this thesis, we propose a framework to fuse an attention-based vision-language model with an ontology system. A convolutional neural network (CNN) with a spatial attention mechanism is invoked for weight feature extraction. A sequence-to-sequence structure with recurrent neural networks (RNN) is then followed, encoding temporal information and mapping from vision to command language. An ontology system, which defines the properties and attributes over various concepts of manipulation in a taxonomic manner, is inferred at last, converting command language into the intended dynamic knowledge graph and governing manipulation concepts with commonsense knowledge.
To evaluate the effectiveness of our framework, we construct a specialized RGB-D dataset with 100K images spanning both robot and human manipulation tasks. The dataset is constructed under a strictly constrained knowledge domain for both robot and human manipulations, with annotated concepts and relations by frame. The performance of our framework is evaluated on our constructed Robot Semantics Dataset, plus an additional public benchmark dataset. Furthermore, ablation studies and online experiments with real-time camera streams are conducted. We demonstrate that our framework works well under the real world robot manipulation scenario, allowing the robot to attend to important manipulation concepts in the pixels and decompose manipulation relations using dynamic knowledge graphs in real time.
The study serves as a fundamental baseline to process robotic vision along with natural language understanding. In future, we aim to enhance this framework further for knowledge-guided assistive robotics.